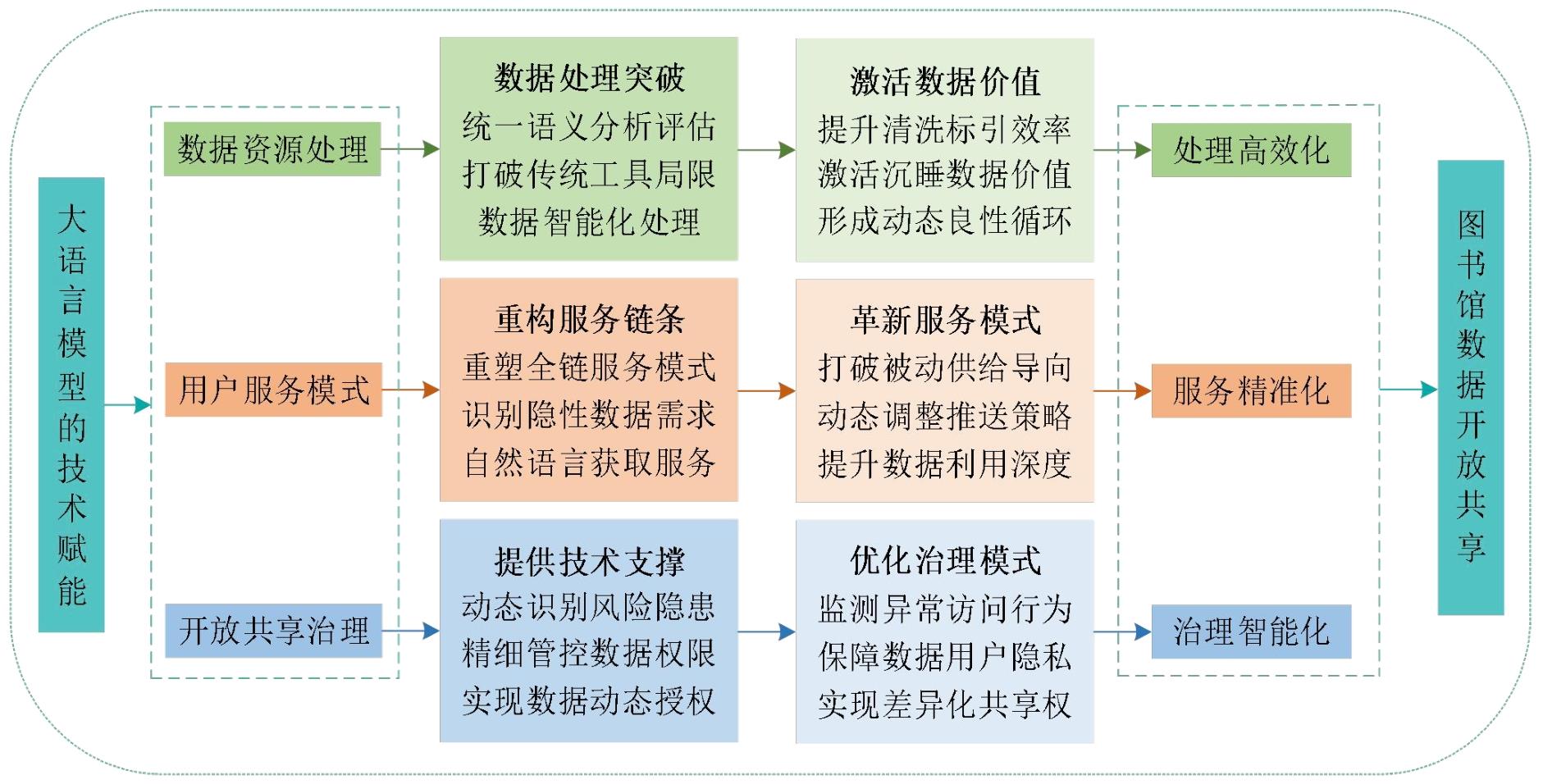
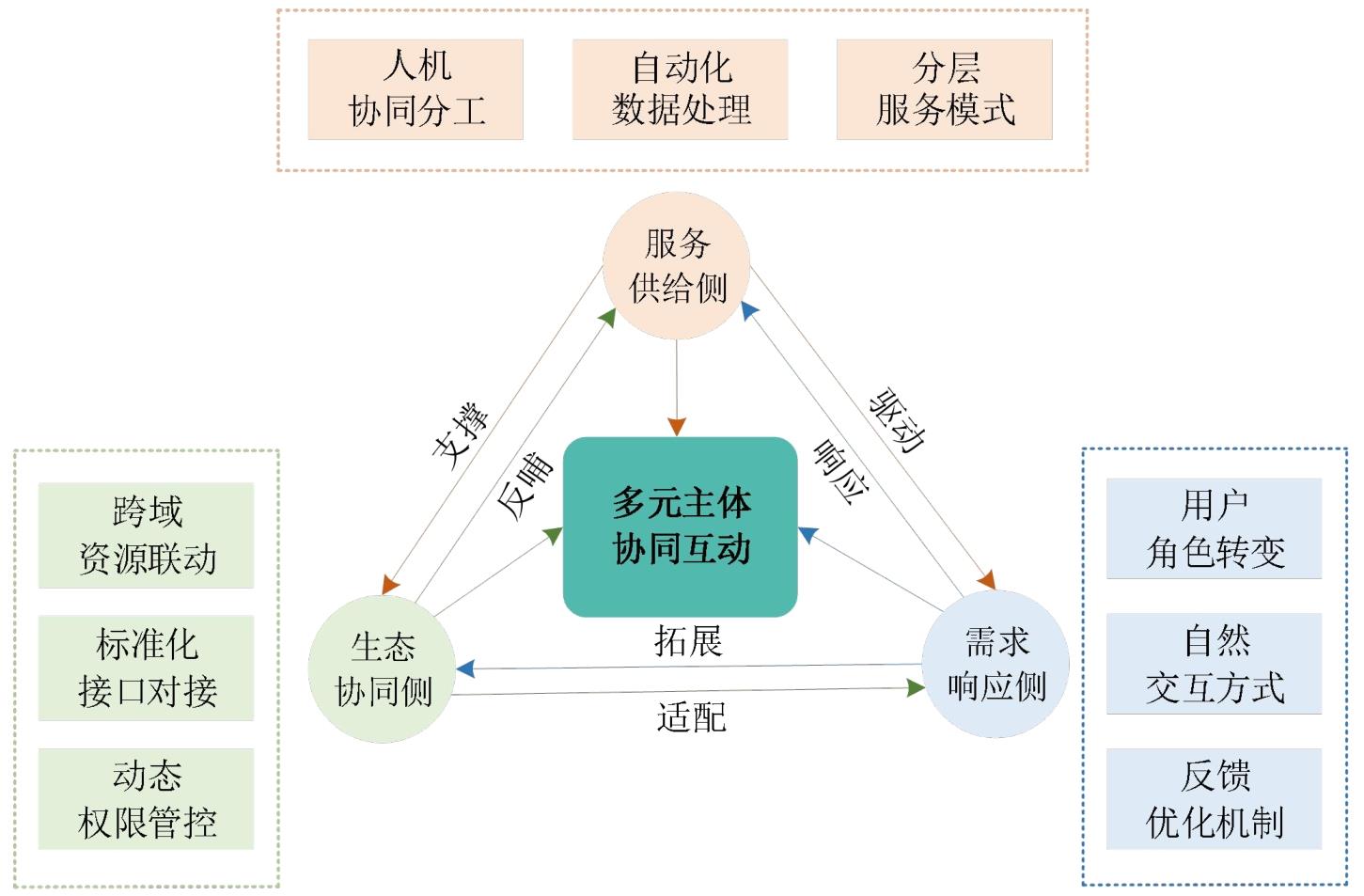
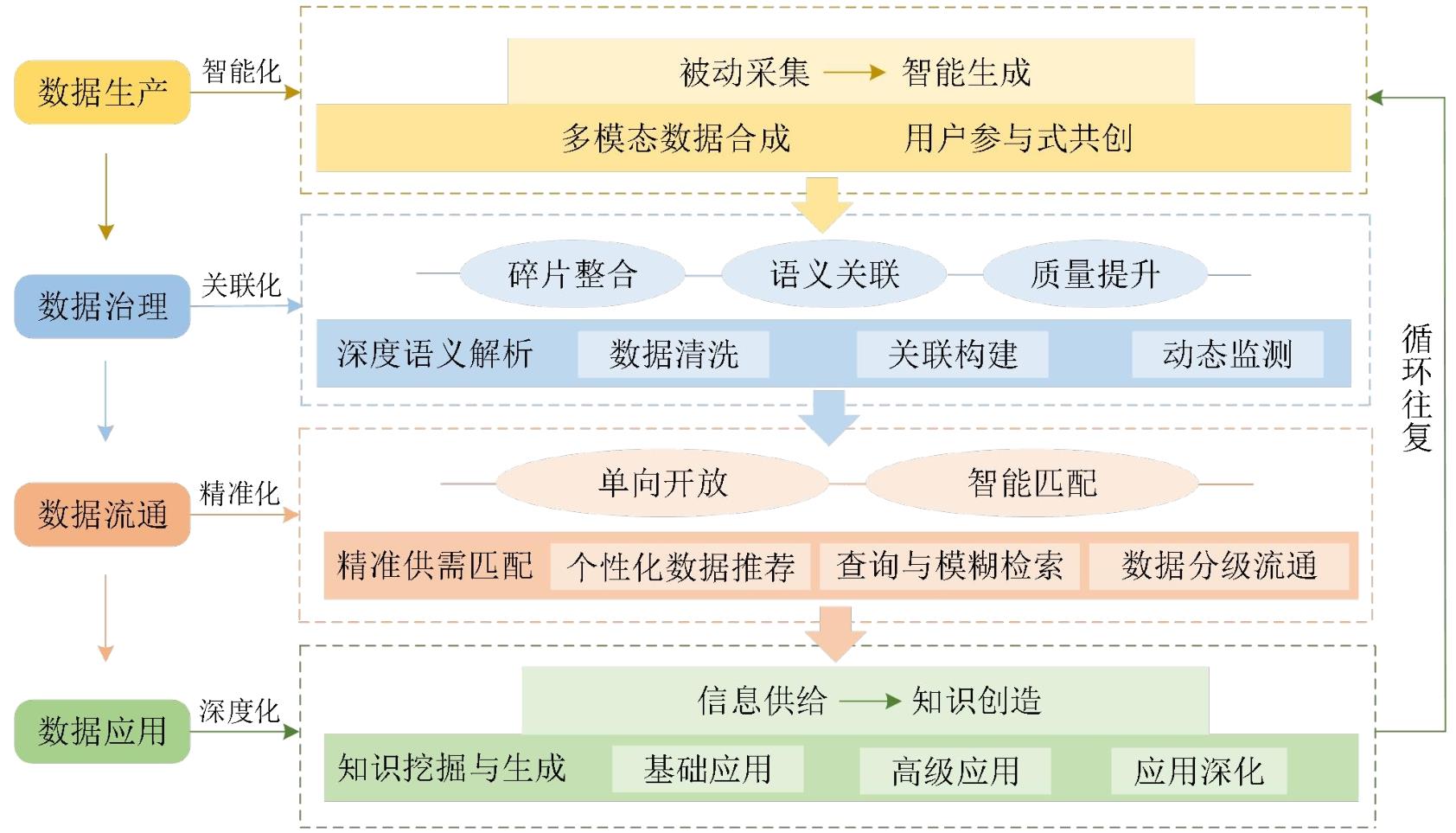
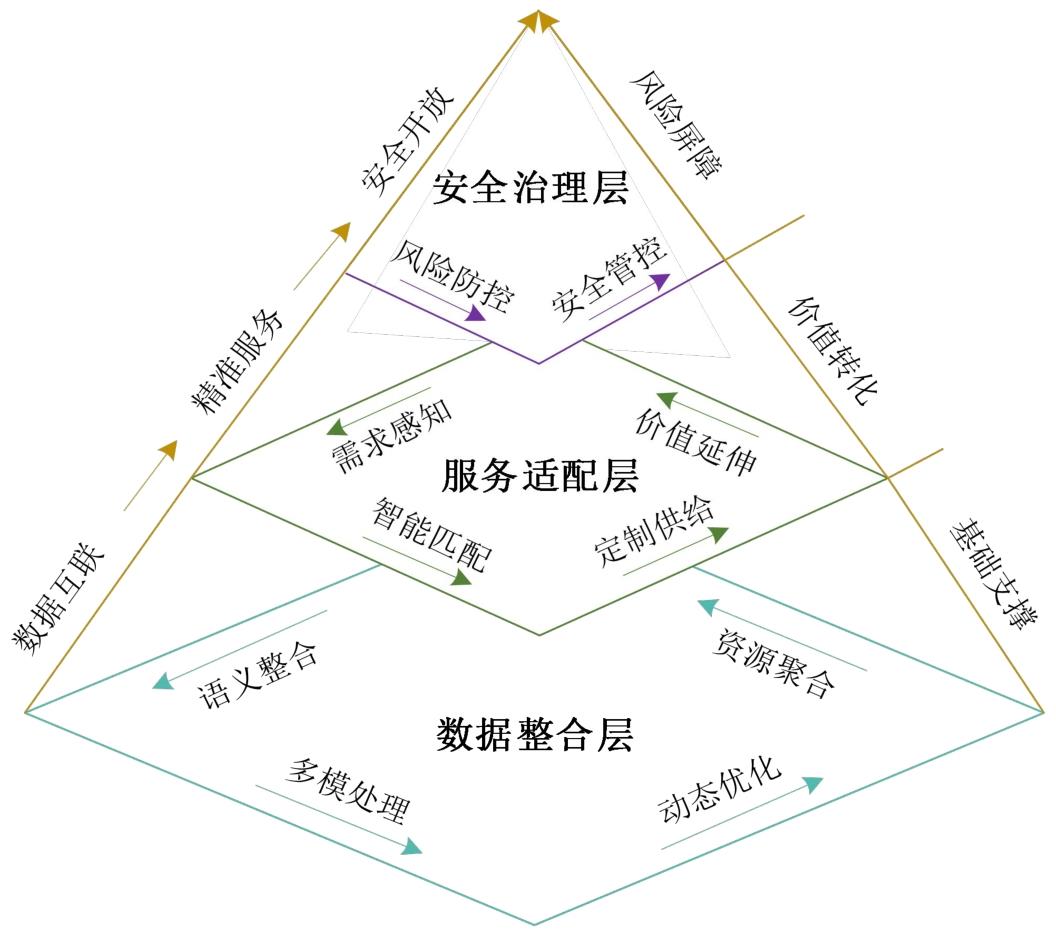
| 维度特征 | 传统图书馆数据开放共享 | 大语言模型赋能的图书馆数据开放共享 |
|---|---|---|
| 数据处理方式 | 以结构化数据为主,依赖人工标引与格式转换,多源异构数据整合难度大 | 支持多模态数据(文本、图像、音频等)语义解析,实现自动化清洗与关联挖掘 |
| 用户交互模式 | 基于关键词检索的被动响应,用户需掌握专业检索技能 | 自然语言对话式交互,支持模糊查询与上下文理解,适配零技术门槛用户 |
| 服务触达范围 | 局限于馆藏目录等基础资源,个性化服务依赖人工定制 | 覆盖科研数据、用户行为等深度资源,通过智能推荐实现“千人千面”服务 |
| 开放效率与成本 | 数据审核流程繁琐,更新滞后,人力与时间成本高 | 自动化合规性校验与动态更新,显著降低运营成本,提升开放时效性 |
| 安全管控机制 | 静态权限划分,难以平衡开放与隐私保护 | 动态风险识别与精细化脱敏,基于场景智能调整数据开放粒度 |
| 价值转化路径 | 以数据供给为核心,价值实现依赖用户自主挖掘 | 嵌入知识生成环节,提供数据洞察报告与决策支持,直接驱动价值创造 |
| 技术支撑体系 | 依赖关系型数据库与基础检索工具,扩展性有限 | 基于分布式算力与预训练模型,支持跨库关联与深度知识推理 |